近日,海外知名大模型產品平臺OpenPipe公布了一項令人矚目的研究成果,該研究成功地在重度推理游戲《時空謎題》中,利用一種名為GRPO的強化學習算法,使小型開源模型的表現超越了多個業界領先的推理模型,包括DeepSeek R1、OpenAI的o1和o3-mini,以及Anthropic的Claude Sonnet 3.7。
這項研究的作者是來自Ender Research的強化學習專家Brad Hilton和OpenPipe的創始人Kyle Corbitt。他們的研究表明,通過精心設計的訓練策略,不僅顯著縮小了與Claude Sonnet 3.7在推理能力上的差距,還實現了超過百倍的成本優化。
報告詳細闡述了任務設計與超參數調整的過程,并分享了基于torchtune框架構建的完整訓練方案,為業界提供了寶貴的參考。
自OpenAI去年發布o系列推理模型以來,大型語言模型(LLMs)在強化學習(RL)訓練下迎來了飛速發展。然而,盡管取得了顯著進展,邏輯演繹能力仍是頂尖模型的短板。當前LLMs普遍難以穩定追蹤細節、保持邏輯嚴密以及實現多步銜接的可靠性。即便是頂尖模型,在生成長輸出時也常出現低級錯誤。
面對這一挑戰,研究團隊決定從小型開源模型入手,探索其在全新推理任務上的潛力。他們選擇了《時空謎題》作為實驗平臺,這是一款靈感源自經典桌游Clue的單人邏輯謎題,不僅包含了標準的推理要素,還增加了時間和動機兩個維度,使得謎題更加復雜且富有挑戰性。
在基準測試中,Claude Sonnet 3.7在設定6.4萬個token的情況下表現最佳,而DeepSeek R1與OpenAI的o1和o3-mini表現相近。相比之下,未經調優的小型開源模型Qwen則顯得遜色。然而,研究團隊相信,只要方法得當,這些小型模型同樣能達到前沿水平。
為了訓練出具有前沿推理能力的模型,研究團隊采用了強化學習方法,并選用了DeepSeek模型的GRPO算法。他們讓大語言模型針對每個謎題生成多個回復,并通過正向強化和懲罰機制來引導模型學習正確的推理過程。在訓練過程中,他們還使用了vLLM推理引擎、HuggingFace Transformers AutoTokenizer等工具來處理回復和數據打包。
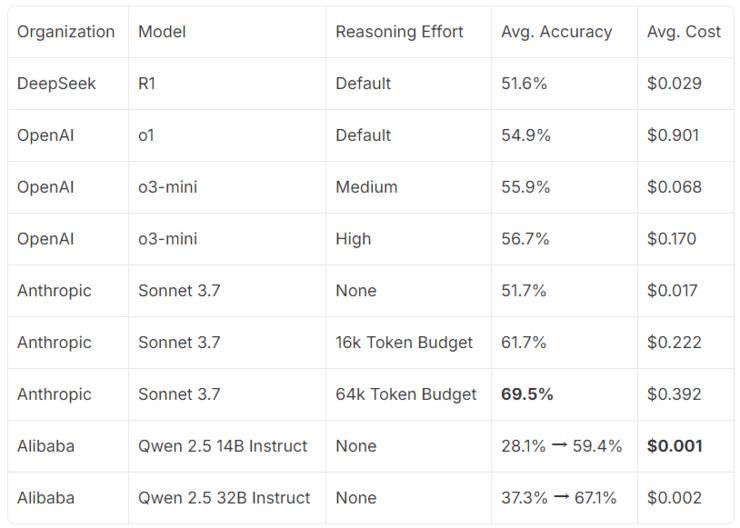
經過上百次的迭代訓練,研究團隊成功地將Qwen模型提升到了前沿推理水平。在最佳狀態下,140億參數的Qwen模型在1.6萬個token的設置下已接近Claude Sonnet 3.7的性能,而320億參數的模型則幾乎達到了Sonnet的結果。研究還發現,在訓練過程中,輸出長度呈現出有趣的規律,這可能與模型的推理能力提升有關。
為了從定性角度評估邏輯推理能力的提升,研究團隊還讓Claude Sonnet 3.7對訓練后的Qwen 32B模型的推論進行識別。結果顯示,Sonnet從基礎模型中識別出的推論大多被判定為錯誤,而從訓練后的模型中識別出的推論則大多被判定為邏輯合理。
最后,研究團隊還估算了Qwen模型的成本效益。他們發現,在假設按需部署具有足夠吞吐量的情況下,訓練后的模型在準確性和推理成本之間實現了顯著的權衡優化。
這項研究不僅展示了強化學習在訓練小型開源模型處理復雜演繹任務方面的巨大潛力,還為業界提供了寶貴的經驗和參考。未來,隨著技術的不斷發展,我們有理由相信,更多的小型模型將能夠通過強化學習實現前沿水平的推理能力。