在人工智能界掀起波瀾的DeepSeek團隊,于近日震撼發布了其最新力作——DeepSeek-R1模型。這款開源模型一經問世,便在Github平臺上迅速積累了超過4000顆星的矚目成績,成為大模型領域的一顆璀璨新星。
DeepSeek-R1的問世,不僅有力回擊了此前關于其借鑒OpenAI o1的質疑,團隊更是直接宣稱:“我們的R1能與開源版的o1平分秋色。”這一自信宣言,無疑為業界帶來了新的震撼。
尤為DeepSeek-R1在訓練方式上實現了重大突破,摒棄了傳統的SFT數據依賴,完全通過強化學習(RL)進行訓練。這一創新之舉,標志著R1已經具備了自我思考的能力,更加貼近人類的思維邏輯。

R1的卓越表現,讓眾多網友將其譽為“開源LLM界的AlphaGo”。在數學、代碼、自然語言推理等多個領域,R1均展現出了與o1正式版不相上下的實力,甚至在某些基準測試中更勝一籌。
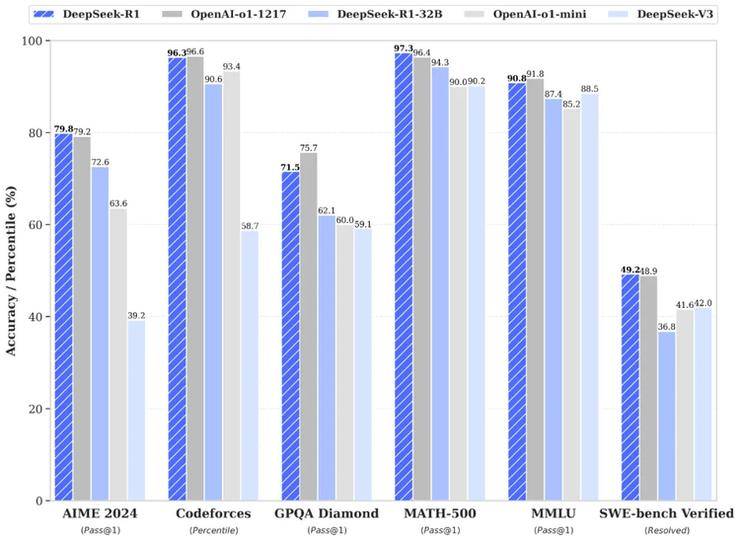
例如,在AIME 2024數學競賽中,DeepSeek-R1取得了79.8%的優異成績,略高于OpenAI的o1-1217。在MATH-500測試中,R1更是以97.3%的高分與o1-1217并駕齊驅,同時遠超其他模型。在編程競賽方面,R1同樣表現出色,其在Codeforces上的Elo評級達到了2029,超越了96.3%的人類參賽者。
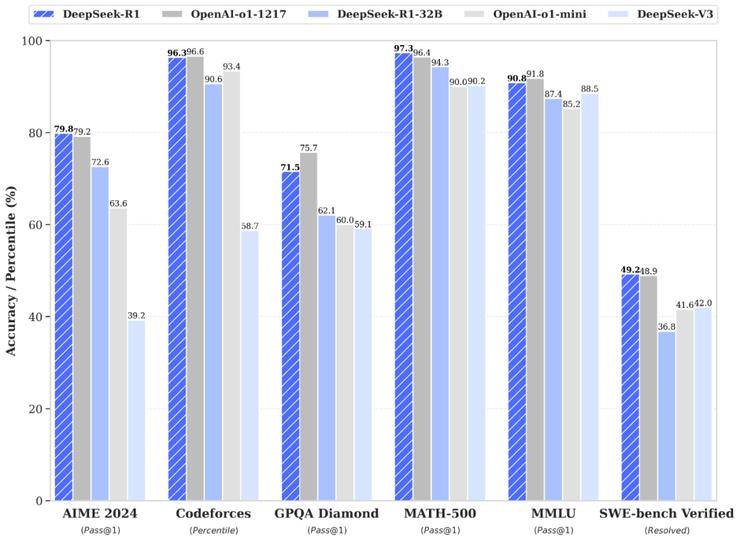
DeepSeek團隊還將R1蒸餾出了6個小模型并開源給社區,參數從1.5B到70B不等。其中,蒸餾過的R1 32B和70B模型在性能上不僅超越了GPT-4o、Claude 3.5 Sonnet和QwQ-32B,甚至與o1-mini的效果相當。更令人驚嘆的是,R1在實現這些卓越性能的同時,成本僅為o1的五十分之一。
除了R1在基準測試中的優異表現外,其發布即開源的訓練數據集和優化工具也贏得了眾多網友的贊譽。他們紛紛表示,這才是真正的Open AI精神。
DeepSeek-R1的成功背后,離不開其三大核心技術的支撐:Self play、Grpo以及Cold start。DeepSeek團隊此次開源的R1模型共有兩個版本,分別是DeepSeek-R1-Zero和DeepSeek-R1,兩者均擁有660B的參數,但功能各有特色。
DeepSeek-R1-Zero完全摒棄了SFT數據,僅通過強化學習進行訓練,實現了大模型訓練中首次跳過監督微調的壯舉。而DeepSeek-R1則在訓練過程中引入了少量的冷啟動數據,并通過多階段強化學習優化模型,極大提升了模型的推理能力。
DeepSeek-R1在訓練過程中還出現了“頓悟時刻”,模型自發地學會了“回頭檢查步驟”的能力。這一能力的涌現,并非程序員直接教授,而是在算法通過獎勵正確答案的機制下自然形成的。這一發現,無疑為人工智能的發展帶來了新的啟示。