近日,SuperCLUE中文大模型測評基準發布了最新的測評報告,該報告針對接入了DeepSeek-R1技術的10家第三方平臺進行了全面的聯網搜索能力評估。此次測評不僅涵蓋了文化生活、經濟生活、實時新聞等基礎檢索內容,還深入考察了各平臺在推理計算、分析排序、數據檢索與分析等分析推理能力上的表現。
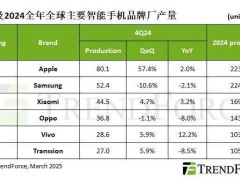
測評結果顯示,各平臺在整體表現上呈現出較大的差異。其中,騰訊元寶憑借出色的綜合實力脫穎而出,成為了此次測評的佼佼者。在總榜單上,騰訊元寶不僅獨占鰲頭,還在分析推理能力榜單上位居首位,展現了其強大的聯網搜索和分析推理能力。
緊隨騰訊元寶之后的是階躍AI和支付寶百寶箱,它們分別位列總榜單的第二和第三位。百度AI搜索和天工AI(高級模式)則以并列第四名的成績緊隨其后,而飛書知識問答和秘塔AI搜索(深入模式)則并列第五。這些平臺在測評中均展現出了不俗的實力,但相較于騰訊元寶仍存在一定的差距。
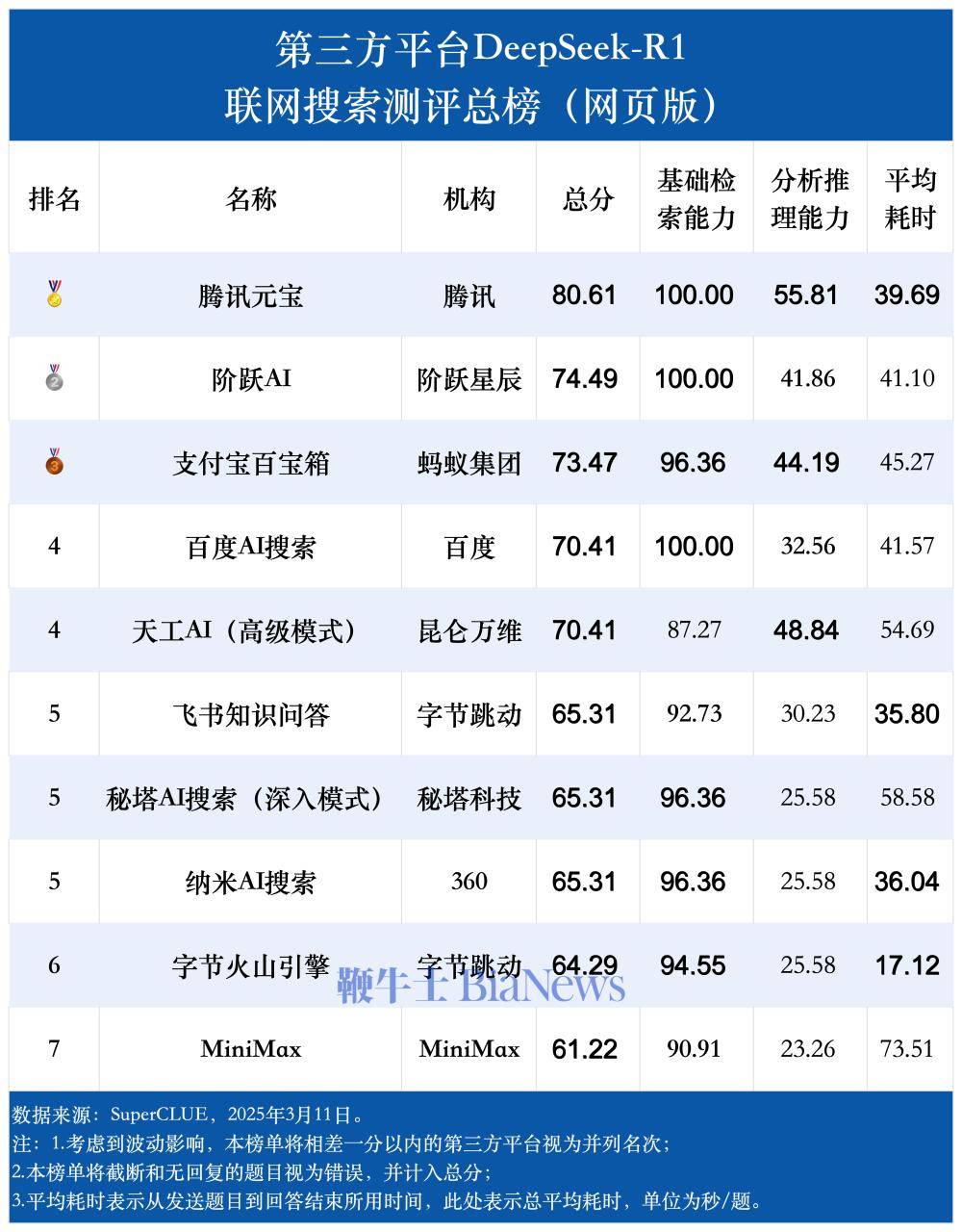
在基礎檢索能力方面,騰訊元寶、階躍AI和百度AI搜索均達到了100%的準確率,這一成績無疑是對它們搜索技術精準度的肯定。然而,在分析推理能力這一更為復雜的測評維度上,僅有騰訊元寶、天工AI、支付寶百寶箱和階躍AI得分超過了40分,顯示出這一領域對于技術實力的更高要求。
報告還指出,各平臺在平均耗時方面同樣存在顯著差異。從最少的字節火山引擎(每題耗時17.12秒)到最多的MiniMax(每題耗時73.51秒),不同平臺之間的搜索效率差距顯著。這一差異不僅體現在總平均耗時上,還體現在不同任務上的平均耗時差異上。整體來看,各平臺的耗時分布范圍較廣,搜索效率差異明顯。
所有平臺在分析推理能力上的平均耗時都明顯高于基礎檢索能力。這進一步說明,分析推理能力相較于基礎檢索能力來說更為復雜和耗時,需要平臺具備更強的技術實力和算法優化能力。