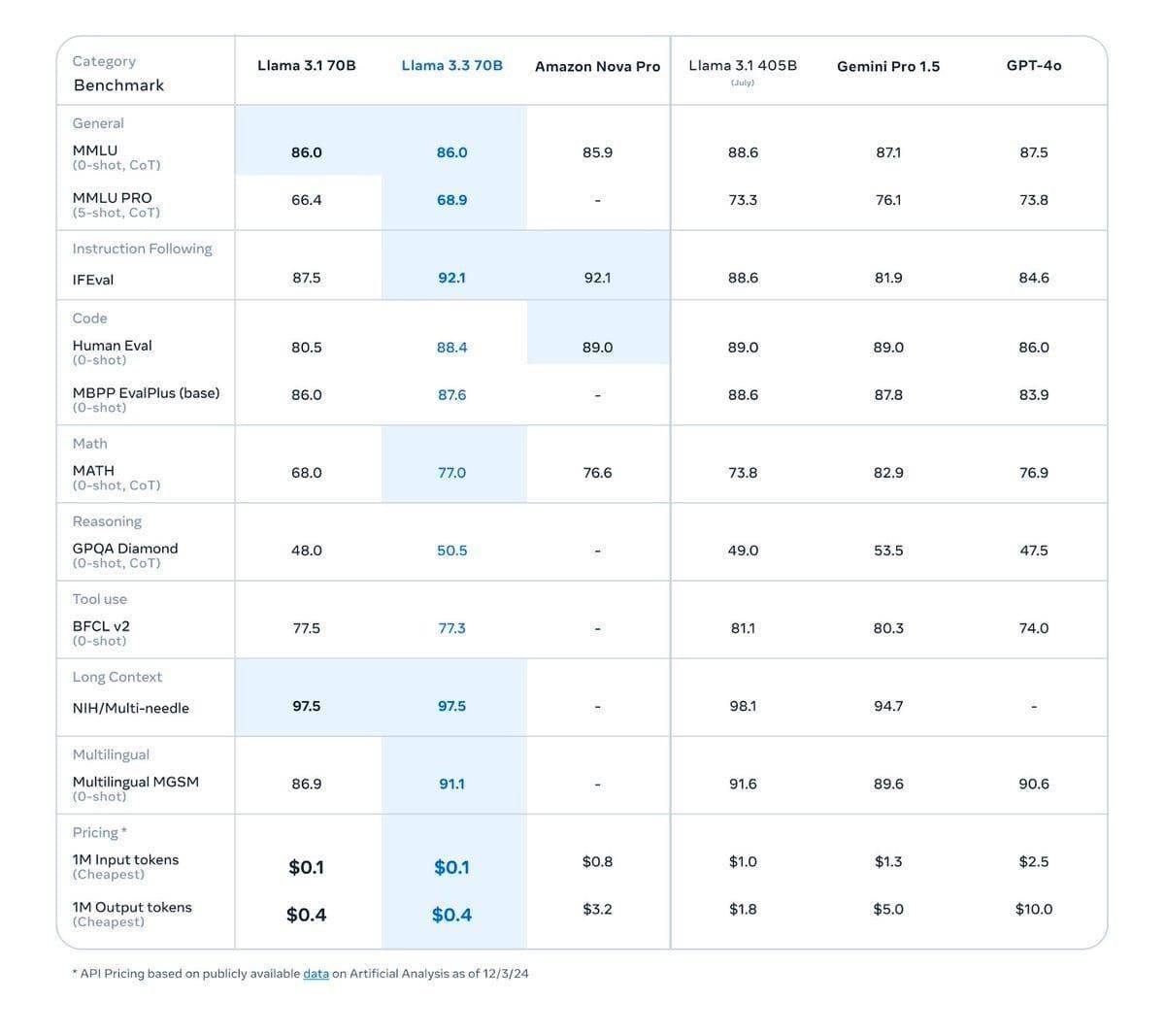
meta近期在人工智能領域再次發力,推出了其年度重量級大模型——Llama 3.3。這款新模型在參數規模上雖然只有700億,但在性能表現上卻能媲美參數高達4050億的Llama 3.1版本,展現了極高的效率。
meta公司特別強調,Llama 3.3不僅在性能上有所提升,更重要的是其成本效益顯著。這款模型能夠在標準工作站上順利運行,極大地降低了運營成本,同時依然能夠為用戶提供高質量的文本AI解決方案。這對于那些希望在AI領域有所作為但又面臨資金壓力的企業和個人來說,無疑是一個巨大的福音。
在功能方面,Llama 3.3也進行了全面優化。它支持多達8種語言,包括英語、德語、法語、意大利語、葡萄牙語、印地語、西班牙語和泰語,滿足了全球不同地區用戶的多樣化需求。這一改進使得Llama 3.3在跨國企業和多語言環境下的應用中更具競爭力。
從架構上來看,Llama 3.3采用了優化的Transformer架構,并采用了自回歸(auto-regressive)語言模型的設計。其微調版本更是結合了監督式微調(SFT)和基于人類反饋的強化學習(RLHF),使得模型在有用性和安全性方面更加符合人類的偏好。這一設計不僅提升了模型的性能,還增強了其在實際應用中的可靠性。
Llama 3.3還具備強大的上下文處理能力和多種工具使用格式支持。其上下文長度可達128K,能夠處理更加復雜和豐富的文本信息。同時,它還支持與外部工具和服務集成,進一步擴展了模型的功能和應用場景。
在安全性方面,meta也采取了多項措施來降低模型濫用的風險。這包括數據過濾、模型微調和系統級安全防護等。同時,meta還鼓勵開發者在部署Llama 3.3時采取必要的安全措施,如使用Llama Guard 3、Prompt Guard和Code Shield等工具,以確保模型的負責任使用。這些措施不僅保護了用戶的隱私和數據安全,也提升了模型的社會責任感和可信度。















