近期,生物科技領域迎來了一項重大突破。隨著生物測序技術的飛速發展,全球天然基因庫中已積累了數十億級別的序列數據,其中隱藏著無數具有極高價值的功能基因。然而,遺憾的是,目前僅有少數幾個“明星基因”得到了深入的研究和開發,絕大多數基因仍然處于未被發掘的狀態。
為了改變這一現狀,中國科學院深圳先進技術研究院定量合成生物學全國重點實驗室的合成生物學研究所婁春波團隊,攜手北京大學定量生物學中心的錢瓏團隊,在國際權威學術期刊 Science Advances 上發表了一項開創性研究。他們成功開發出了全球首個專為合成生物學元件挖掘和生物制造應用設計的大語言模型——“SYMPLEX”。

SYMPLEX 模型通過結合領域大語言模型的訓練、合成生物學專家知識的對齊以及大規模生物信息分析,實現了從海量生物學文獻中自動化挖掘功能基因元件,并精準評估這些元件在工程化應用中的潛力。這一突破性的進展,展示了大型語言模型在生物制造領域的巨大應用潛力。
研究團隊將 SYMPLEX 應用于挖掘 mRNA 疫苗生物制造中的關鍵酶——加帽酶。通過這一模型,他們成功發現了多種高性能的新型加帽酶。經過第三方公司的實驗驗證,這些新型加帽酶的催化效率遠超國際知名生物科技公司 New England Biolabs(NEB)的商業化加帽酶,催化效率提高了兩倍以上,從而顯著提升了 mRNA 疫苗的生產效率和成本效益。
研究團隊的創新之處在于,他們將大型語言模型(LLM)與結構化的生物知識庫進行了深度融合,開發出 SYMPLEX 智能基因挖掘平臺。這一平臺能夠自動化閱讀和理解海量的生物學文獻,從基因、功能和知識三個層面對文獻內容進行提取和分析。通過與專家數據庫進行概念對齊和交互,以及基于先進生物信息技術的統計模式生成,SYMPLEX 能夠提供具有完整證據鏈的高質量候選基因集合。
SYMPLEX 不僅有效避免了大型語言模型可能出現的幻覺問題,還能夠自動生成與基因功能相關的細粒度知識樹。這一功能為科學家提供了寶貴的工具,引導他們深入探索廣泛的生物機制和分子過程。

與傳統基因挖掘流程相比,SYMPLEX 大模型在挖掘基因的深度、數量和多樣性方面都表現出顯著的優勢。其挖掘的基因多樣性甚至超越了現有蛋白質功能預測模型的邊界。這一突破性的進展,無疑為生物科技領域帶來了新的希望和機遇。
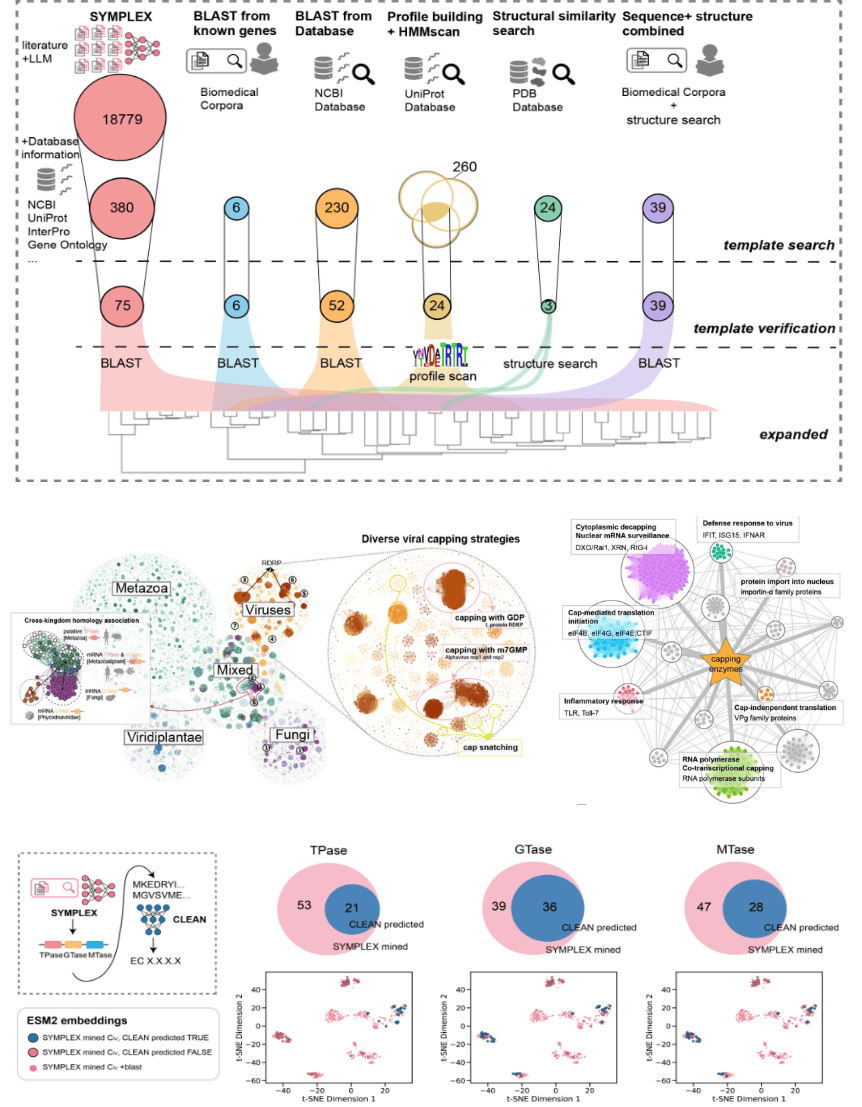
目前,SYMPLEX 在線交互式平臺已經正式上線,供研究人員使用。該平臺采用模塊化設計,提供了三個核心功能:文獻智能提取引擎 PubEngine,支持高通量的文獻智能檢索分析與可視化交互;基因功能標注系統 GeneTagger,實現從分子機制到生物過程的細粒度自動化基因與功能提取;以及標準化知識中樞 GeneNorm,實現與專家知識庫的概念對齊與標準化,支持知識樹構建和功能模式識別。