在人工智能領(lǐng)域,Manus智能體的出現(xiàn)引發(fā)了廣泛的討論與關(guān)注。Manus憑借其獨特的定位,成功將智能體概念從抽象推向具體,盡管業(yè)界對其技術(shù)創(chuàng)新的質(zhì)疑聲不斷,認為Manus更多是現(xiàn)有技術(shù)的融合而非底層創(chuàng)新。
在AI智能體推理與決策研討會(AIR 2025)上,來自倫敦大學學院、新加坡南洋理工大學、Weco AI、Google DeepMind、meta、華為、阿里等多位學術(shù)界和工業(yè)界的研究人員圍繞強化學習、推理決策、AI智能體展開了深入討論。這些討論不僅揭示了智能體技術(shù)的最新進展,也探討了未來可能的發(fā)展方向。
新加坡南洋理工大學的安波教授在研討會上分享了團隊在智能體技術(shù)上的最新成果。他詳細闡述了從基于強化學習的智能體到由大型語言模型驅(qū)動的智能體的演變過程,并介紹了Q*算法。該算法通過多步驟推理進行審慎規(guī)劃,并在學習Q值模型的過程中,采用離線強化學習、最佳回滾軌跡獎勵以及與更強大LLM共同完成的軌跡獎勵三個關(guān)鍵步驟。
初創(chuàng)公司W(wǎng)eco AI的CTO Yuxiang則介紹了AIDE,一個由人工智能驅(qū)動的Agent,能夠處理完整的機器和工程任務。Yuxiang將機器學習和工程視為代碼優(yōu)化問題,將整個過程形式化為在解空間中的樹搜索。AIDE能夠在任何大語言模型編寫的代碼空間中進行搜索,從而找到最優(yōu)解。
倫敦大學學院的宋研討論了強化學習在大型語言模型推理中的作用,并指出DeepSeek模型在強化學習階段學會了自我糾正。這一現(xiàn)象表明,大型語言模型在基礎模型已具備自我糾正能力的基礎上,通過強化學習可以進一步提升其性能。
Google DeepMind的研究員馮熙棟則提出了一種新的理念,即將強化學習的組成部分用自然語言描述出來。他嘗試將策略、值函數(shù)、貝爾曼方程等傳統(tǒng)強化學習概念映射到自然語言表示空間中,從而重新定義強化學習。
在研討會上,來自華為倫敦的邵坤介紹了面向通用型GUI Agent的模型和優(yōu)化方法。他展示了GUI Agent在不同任務中的表現(xiàn),并討論了如何通過生成模型、Agent系統(tǒng)、微調(diào)和評估等方法來提升GUI Agent的性能和效率。
阿里通義千問的林俊旸則分享了Qwen大模型在數(shù)據(jù)量、模型規(guī)模和上下文長度擴展方面的最新進展。他透露,Qwen 2.5版本的數(shù)據(jù)量已擴展到18T,并計劃使用更多token進行訓練。同時,Qwen在模型規(guī)模和上下文長度擴展方面也取得了顯著進展,能夠處理更長的文本和更復雜的任務。
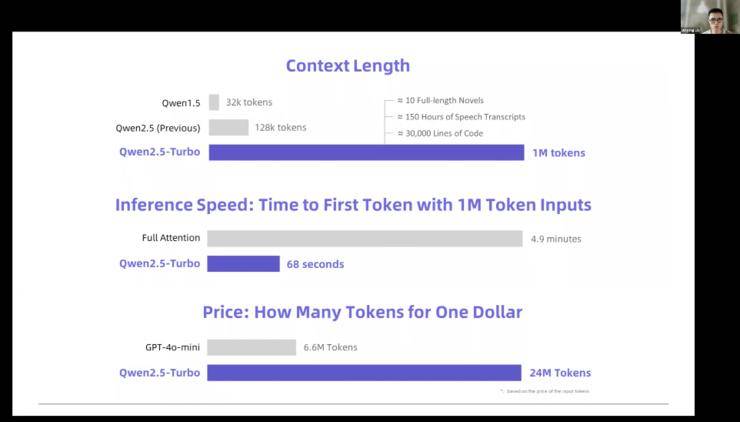
這些研究成果不僅展示了AI智能體技術(shù)的最新進展,也為未來智能體技術(shù)的發(fā)展提供了重要參考。隨著技術(shù)的不斷進步和應用場景的不斷拓展,AI智能體將在更多領(lǐng)域發(fā)揮重要作用。