百度近期在人工智能領域再度取得突破,于1月23日正式揭曉了其最新研發(fā)成果——EICopilot。這一創(chuàng)新解決方案利用大型語言模型(LLM)技術,極大地簡化了從復雜數(shù)據(jù)庫中提取信息的流程,為企業(yè)知識圖譜的探索和應用提供了強有力的支持。
在當前的企業(yè)環(huán)境中,知識圖譜因其能夠整合法人、注冊資本、股東信息等多維度數(shù)據(jù)而備受青睞。然而,盡管知識圖譜的應用價值顯著,但傳統(tǒng)的文本查詢和手動探索方式卻限制了其信息提取的效率。為了解決這一難題,百度研究院精心打造了EICopilot。
EICopilot作為一個基于AI智能體的解決方案,專注于優(yōu)化存儲在知識圖譜數(shù)據(jù)庫中的企業(yè)數(shù)據(jù)的搜索、探索和摘要過程。它能夠高效地處理包含數(shù)億節(jié)點、數(shù)百億邊、數(shù)千億屬性以及數(shù)百萬子圖的龐大數(shù)據(jù)集,這些數(shù)據(jù)集涵蓋了國家注冊的企業(yè)、組織、公司等各類信息。
為了提升搜索精度,百度研究人員收集了真實的企業(yè)相關查詢,構建了種子數(shù)據(jù)集,并使用Gremlin語言編寫了搜索腳本。通過系統(tǒng)的標注和增強,這些數(shù)據(jù)被轉化為向量數(shù)據(jù)庫,從而實現(xiàn)了搜索空間的實時生成,極大地提高了圖譜檢索和探索的效率。
EICopilot不僅是一個基于LLM的聊天機器人,還具備創(chuàng)新的數(shù)據(jù)預處理流程,能夠優(yōu)化數(shù)據(jù)庫查詢。它還擁有強大的推理能力,采用思維鏈(CoT)和上下文學習(ICL)等先進技術,為用戶提供更加精準和有價值的查詢響應。
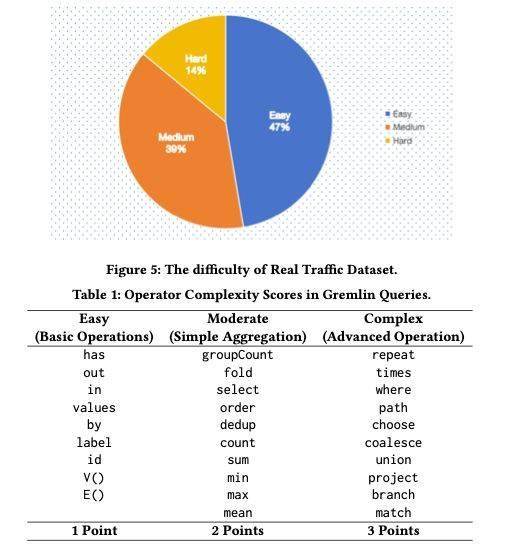
為了驗證EICopilot的性能,研究人員利用百度內(nèi)部數(shù)據(jù)平臺的數(shù)據(jù),構建了一個包含查詢和圖數(shù)據(jù)庫查詢對的數(shù)據(jù)集。根據(jù)查詢的遍歷長度,他們將查詢分為簡單、中等和復雜三類,并采用語法錯誤率(SyntaxErrorRate)和執(zhí)行正確率(Execution Correctness)作為評估指標。實證結果表明,EICopilot在速度和準確性方面均優(yōu)于基線方法,F(xiàn)ull Mask版本的EICopilot語法錯誤率低至10.00%,執(zhí)行正確率高達82.14%。
這一突破性成果不僅展示了百度在人工智能領域的深厚積累,也為企業(yè)知識圖譜的探索和應用開辟了新的道路。EICopilot的推出,無疑將為企業(yè)用戶提供更加便捷、高效的信息提取和數(shù)據(jù)分析服務。